Edge Computing Lab: TinyML Workshop
Overview
In 2022 and 2023 Google engineers and a group of researchers from Harvard’s Edge Computing Lab collaborated to hold a workshop series on accelerating ML tasks on resource constrained devices (Prakash et al., 2022). The workshops centered on using the CFU-Playground framework to optimize frequently used instructions, and deploy the optimized hardware on a selection of FPGA development boards. I worked with members of the Edge Computing Lab to test core components of the workshop including profiling ML programs and deploying custom function units (CFUs).
Testing
Testing began with deploying models to run on a system on chip (SoC). CFU-Playground leveraged the LiteX SoC framework to build an SoC composed of a VexRiscV soft CPU, and drivers for communication with external RAM and USB-UART. The setup additionally includes an extension for the CPU to communicate with a CFU through a default op code. CFU-Playground includes several TensorFlow Lite for Microcontrollers (TFLM) machine learning models. Among these were an image classification model, and a “yes”/”no” speech recognition model, on which most of my testing centered. The project is preloaded with Makefiles for initiating bitstream synthesis, and compiling models to the SoC (Green et al., 2020).
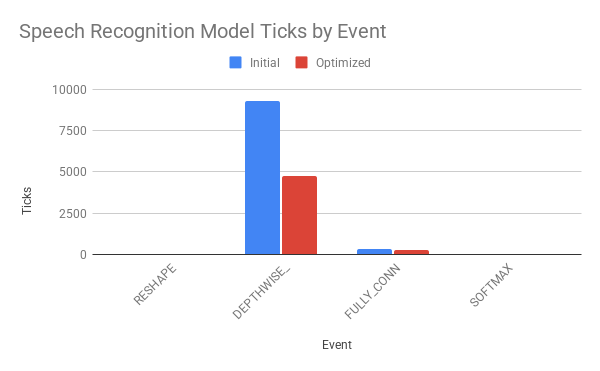
Once I had deployed the models I profiled them to identify suitable opportunities for optimization. Profiling involved both tracking cycles spent on each operation and inserting counters to track the frequency of entering various loops in the model. Results from profiling informed software and hardware optimizations of the models. Software optimizations included loop unrolling and hardcoding constant convolution parameters. From the distribution of cycle counts in the models, I identified 2D convolution and depthwise convolution as the most applicable operations to optimize in the image classification and speech recognition models respectively.
Within the convolution operations, performance counters further revealed the multiply and accumulate step to be the most computationally intensive portion. I deployed a Verilog CFU which executed a multiply as a SIMD instruction before accumulating the data. I reprofiled the models after editing the 2D and depthwise convolution TFLM kernels to employ the CFU. The optimizations led to a 53% decrease in the number of cycles spent running the image classification model, and a 47% decrease in the speech recognition model.